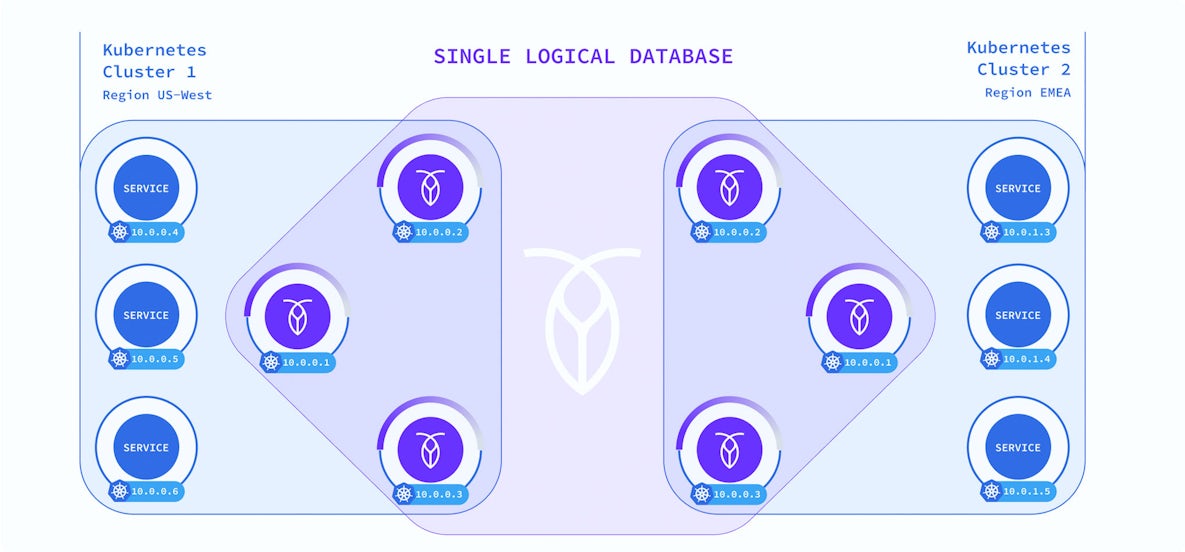
Since this post was originally published in 2017, StatefulSets have become common and allow a wide array of stateful workloads to run on Kubernetes. In this post, we’ll quickly walk through the history of StatefulSets, and how they fit with CockroachDB and Kubernetes, before jumping into a tutorial for running CockroachDB on Kubernetes.
-–
Managing resilience, scale, and ease of operations in a containerized world is largely what Kubernetes is all about—and one of the reasons platform adoption has doubled since 2017. And as container orchestration continues to become a dominant DevOps paradigm, the ecosystem has continued to mature with better tools for replication, management, and monitoring of our workloads.
And as Kubernetes grows, so does CockroachDB as we’ve recently simplified some of the day 2 operations associated with our distributed database with our Kubernetes Operator. Ultimately, however, our overall goal in the cloud-native community is singular: ease the deployment of stateful workloads on Kubernetes.
Bringing State to Kubernetes
CockroachDB helps solve for stateful, database-dependent applications through replication of data across independent database nodes in a way that will survive any failure (just in case our name didn’t make total sense). CockroachDB, combined with Kubernetes’ built-in scale out, survivability and replication strategies, can give you the speed and simplicity of orchestration without sacrificing the high availability and correctness you expect from critical stateful databases.
How do CockroachDB + Kubernetes = Retained State?
While Kubernetes is fairly straightforward for use with stateless services, management and surviving state has been a challenge.
Why? You can’t simply swap out nodes as they depend on data in pod-mounted storage. And rolling back doesn’t work for databases either.
Some best practices have evolved to workaround the challenge of deploying data-driven apps on K8s:
- Run the database outside of Kubernetes: This creates lots of extra work, adds redundant tooling, and can actually invalidate the value you were looking to gain from K8s.
- Use a DBaaS: This, too, limits the value of scale and resilience of Kubernetes and limits your choice to only those options provided by your Cloud Service Provider
To keep up with the demands of modern, data-driven apps, the Kubernetes community developed a native way to manage state, via StatefulSets.
- StatefulSets assign a unique ID that keeps application and database containers connected through automation.
- Note: The use of “Unique ID” is a bit tricky here. Each resource in kubernetes gets UID to identify it but that UID will change whenever the resource is updated. StatefulSets assign pod identity which is persistent across pod generations but is separate from UIDs.
StatefulSets are ideal for CockroachDB because the UID means it doesn’t get treated as a new node in a Kubernetes cluster, cutting way back on the amount of data replication required to keep data available. This is key to efficiently supporting fast distributed transactions and our consensus protocol. For a real life example of a CockroachDB running on Kubernetes to retain state check out this Pure Storage case study.
Step By Step Kubernetes Tutorial
Before you begin building your own Kubernetes cluster you may need to visit our documentation for ‘starting Kubernetes’ and ‘starting CockroachDB’. That doc contains those detailed steps including details about installing the operator, initializing the cluster and using the built-in SQL Client.
Step One: Building Your Kubernetes Cluster
The year is 2021. There are lots of ways to get your Kubernetes cluster up and running. For this walkthrough we’ll use GKE. If you’re interested in other paths, we have resources for:
- Running a cluster locally on Minikube
- Setting a cluster up on AWS
With the Google Cloud CLI installed, create the cluster by running
gcloud container clusters create cockroachdb-cluster
Step Two: Spinning up CockroachDB
Just like most Kubernetes deployment configuration work, CockroachDB config is managed by a YAML file like the one below. We’ve added comments to help provide some context for what’s going on.
- Start by copying the file from our GitHub repository into a file named ‘cockroachdb-statefulset.yaml’. This file defines the resources to be created, in this case including the StatefulSet object that will spin up the CockroachDB containers and then attach them to persistent volumes.
- You’ll then need to create the resources shown below. If you’re using Minikube, you may need to manually provision persistent volumes.
You should soon see 3 replicas running in your cluster along with a couple of services. At first, only some of the replicas may show because they haven’t all yet started. This is normal, as StatefulSets create the replicas one-by-one, starting with the first.
$ kubectl create -f cockroachdb-statefulset.yaml
service "cockroachdb-public" created
service "cockroachdb" created
poddisruptionbudget "cockroachdb-budget" created
statefulset "cockroachdb" created
$ kubectl get services
cockroachdb None <none> 26257/TCP,8080/TCP 4s
cockroachdb-public 10.0.0.85 <none> 26257/TCP,8080/TCP 4s
kubernetes 10.0.0.1 <none> 443/TCP 1h
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cockroachdb-0 1/1 Running 0 29s
cockroachdb-1 0/1 Running 0 9s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
cockroachdb-0 1/1 Running 0 1m
cockroachdb-1 1/1 Running 0 41s
cockroachdb-2 1/1 Running 0 21s
Lifting the Hood
If you’re curious to see what’s happening inside the cluster, check the logs for one of the pods by running kubectl logs cockroachdb-0.
Step Three: Using the CockroachDB cluster
If all has gone to plan, you now have a cluster up and running. Congratulations!
To open a SQL shell within the Kubernetes cluster, you can run a one-off interactive pod like this, using the cockroachdb-public hostname to access the CockroachDB cluster. Kubernetes will then automatically load-balance connections to that hostname across the healthy CockroachDB instances.
$ kubectl run cockroachdb -it --image=cockroachdb/cockroach --rm --restart=Never -- sql --insecure --host=cockroachdb-public
Waiting for pod default/cockroachdb to be running, status is Pending, pod ready: false
Hit enter for command prompt
root@cockroachdb-public:26257> CREATE DATABASE bank;
CREATE DATABASE
root@cockroachdb-public:26257> CREATE TABLE bank.accounts (id INT PRIMARY KEY, balance DECIMAL);
CREATE TABLE
root@cockroachdb-public:26257> INSERT INTO bank.accounts VALUES (1234, 10000.50);
INSERT 1
root@cockroachdb-public:26257> SELECT * FROM bank.accounts;
+------+---------+
| id | balance |
+------+---------+
| 1234 | 10000.5 |
+------+---------+
(1 row)
Step Four: Accessing the CockroachDB Console
To get more information into cluster behavior and health, you can pull up the CockroachDB Console by port-forwarding from your local machine to one of the pods as shown below:
If you want to see information about how the cluster is doing, you can try pulling up the CockroachDB admin UI by port-forwarding from your local machine to one of the pods:
kubectl port-forward cockroachdb-0 8080
You should now be able to access the admin UI by visiting http://localhost:8080/ in your web browser:
Step Five: Simulating node failure
We talked about DB survivability earlier. Now you can test it for yourself. What happens when a pod goes bad or gets deleted?
- To test the resiliency of the cluster, try killing some of the containers by running a command like
kubectl delete pod cockroachdb-3. This must be done from a different terminal while you’re still accessing the cluster from your SQL shell. - If you get a “bad connection” error from deleting the same instance your shell was communicating with, simply retry the query.
The container will now be recreated for you by the StatefulSet controller, just as it would happen in the event of a real production failure.
If you’re up for testing the durability of the cluster data, you can try deleting all the pods at once and ensuring they start up properly again from their persistent volumes. To do this, you can run kubectl delete pod –selector app=cockroachdb, which deletes all pods that have the label app=cockroachdb. This includes the pods from our StatefulSet.
Just like during setup, it might take some time for them all to come back up again. But once they are up and running again, you’ll be able to get the same data back from the SQL queries you’re making in the shell.
Step Six: Scaling the CockroachDB cluster
Before removing nodes from your cluster, you must first tell CockroachDB to decommission them. (This lets nodes finish in-flight requests, rejects any new requests, and transfer all range replicas and range leases off the nodes.
Now that the nodes are decommissioned you can scale your Kubernetes cluster by simply adding or subtracting replicas by resizing the StatefulSet as shown below:
kubectl scale statefulset cockroachdb --replicas=4
Step Seven: Shutting down the CockroachDB cluster
Once you’re done, a single command will clean up all the resources we’ve created during our oh-so-brief Kubernetes tutorial. The labels we added to the resources do all the work.
kubectl delete statefulsets,pods,persistentvolumes,persistentvolumeclaims,services,poddisruptionbudget -l app=cockroachdb
You can also shut down your entire Kubernetes cluster by running:
gcloud container clusters delete cockroachdb-cluster
Next steps for running your database on Kubernetes
-
Write applications that use the CockroachDB cluster via one of the many supported client libraries.
-
Modify how the cluster is initialized to use certificates for encryption between nodes.
-
Set up a cluster in a cloud or bare metal environment using a different kind of PersistentVolume, rather than on Container Engine.
-
Setting up Prometheus to monitor CockroachDB within the cluster, taking advantage of the annotations we put on the CockroachDB StatefulSet.
-
Contribute feature requests, issues, or improvements to CockroachDB, either for the Kubernetes documentation or for the core database itself!
-
Check out more tutorials and tech talks about Kubernetes.
Get started for free with CockroachDB 21.2!
References
More information and up-to-date configuration files for running CockroachDB on Kubernetes can be found in our documentation.

